Quem acompanha meus conteúdos aqui no blogue deve ter percebido que sou um entusiasta dos testes de DNA como auxiliares na pesquisa genealógica. Posso dizer que sou entusiasta e assíduo, pois fiz meu primeiro teste no escopo de um projeto da National Geographic há quase 20 anos e não parei mais. Se os custos ainda parecem altos para a maior parte das pessoas, posso atestar que eles já foram maiores e não é só isso, pois antes só eram feitos no exterior, ainda que se pudesse comprá-los no Brasil. Hoje temos empresas brasileiras que os oferecem a um valor razoável, por isso, sempre que me consultam, sugiro fazer um teste nacional e subir os dados brutos para plataformas como o GEDmatch, por exemplo, pois assim se consegue extrair o máximo valor deles.
Para um iniciante, a vantagem de um testes desses poderia estar apenas nas análises relativas à saúde e bem-estar, talvez mesmo na análise da composição étnica. Para quem busca a Genealogia, no entanto, maior valor sempre será encontrado nas correspondências genéticas (matches), que são as listas de parentes próximos e primos que os laboratórios costumam oferecer. Essas listas nada mais são do que uma relação de outros clientes de um desses laboratórios com quem a pessoa compartilha uma faixa de DNA sugestiva de um parentesco mais ou menos próximo. É fácil deduzir que quanto mais clientes um laboratório possuir, maior será a dimensão da lista de matches que poderá oferecer aos clientes. Mas será mesmo assim?

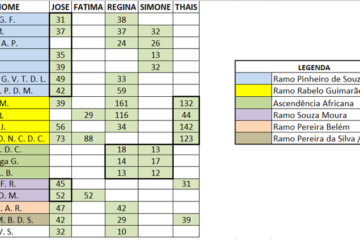
A pergunta tem uma motivação prática: nem todo cliente terá uma lista extensa de matches. Posso comprovar pelo meu caso e os de minhas primas maternas Regina, Simone e Thais. Nossos testes foram feitos há alguns anos pelo laboratório brasileiro Genera. Quando redigi este texto, minha lista continha apenas 81 matches, variando entre 584 cM e 17 cM, sendo cM (centimorgan) uma unidade de medida genética que indica a distância entre dois marcadores ou genes em um cromossomo. O raciocínio, de forma bem simples, é que quanto maior o valor de cM, mais próximo o parentesco. Minha prima Thais, por sua vez, tinha uma lista de correspondências de 765 matches, variando entre 142 cM e 11 cM. A lista da prima Regina tinha 1.488 matches variando entre 584 cM e 10 cM. Prima Simone, finalmente, tinha uma enorme lista com 2.137 matches, variando entre 372 cM e 10 cM.
Vários matches que aparecem na minha lista também aparecem nas listas de minhas primas, o que atesta que meu parentesco com eles se dá por meu ramo materno, visto que não houve parentesco entre meus antepassados paternos e maternos. Em vários casos, pude esclarecer por via documental esse parentesco com meus matches e chegar até nosso antepassado comum. Mas restam ainda muitos casos por esclarecer, o que poderá acontecer futuramente, considerando que essas listas são dinâmicas e tendem a crescer com o tempo. Mas será que crescem mesmo? E como crescem?
A resposta à primeira pergunta é positiva: as listas tendem a crescer. A resposta à segunda é menos positiva: elas não crescem necessariamente da forma desejada pelo cliente. Falo por mim e por alguns outros clientes com quem tenho contato e que também têm listas com poucos matches. Minha lista cresce muito lentamente, tendo na maior parte do tempo permanecido estável. Em dado momento, bastante frustrado com isso, enviei mensagem ao laboratório, que me respondeu que o que eu observava não era um problema, e que o crescimento da lista se dava no sentido do acréscimo de matches realmente relevantes para mim. É neste segundo ponto que surge um elemento importante: quer dizer que há matches não relevantes?
Sim, há, e não são poucos. Eles são conhecidos como falsos matches e sua explicação pode ser encontrada num compartilhamento de DNA por mero acaso, por uma origem étnica comum ou por ascendência familiar em grupos altamente endogâmicos, como as comunidades de judeus ashkenazes. Em todas essas circunstâncias, é bastante improvável que se chegue à identificação do antepassado comum de forma que se consiga esclarecer o parentesco. Outra circunstância que leva aos falsos matches é o compartilhamento de segmentos pequenos – com poucos cM – de DNA. A regra para evitar a perda de tempo com tais matches é sempre considerar segmentos de DNA com, pelo menos, 17 cM a 20 cM – quanto mais, melhor. No caso de uma origem endogâmica, a sugestão é levar em conta apenas matches com valores na casa das centenas de cM.
Um dos ramos maternos de minha árvore familiar revelou inúmeros casamentos consanguíneos, pelo que pude encontrar primos relativamente distantes, no sexto grau, compartilhando 26 cM, com identificação positiva de antepassados em comum. Felizmente, trata-se de um ramo bem estudado por outros genealogistas, ainda que, pela enorme descendência do casal fundador, eu espere ainda esclarecer matches com grau de parentesco até mais distante.
José Araújo é genealogista.